Note: This posting is directly related to my
Perl-Tips blog. I'll shortly be putting up some Perl scripts there to parse web server log files. Please keep an eye on that blog if you are interested.
In the process of parsing a web server log file to analyze visitor data to my blogs, I found myself using a temporary XML file to transfer information between a command-line Perl script and PHP web scripts. (The how and why of this is at my Perl-Tips blog.) So I came up with a very simple XML-based markup language to describe the records of a web server log. A sample is shown below. Note that the data below is based on an "Extended Format" Log File. This is similar to the NCSA Standard format, but also includes the referring web page and the user agent (type of web browser or other software used to "visit" the page). Microsoft log files follow a slightly different format and are not discussed here.
<?
xml version="1.0" ?>
<
serverlog_partial domain="chameleonintegration.com">
<
logentries>
<
serverlogentry id="1" clientip="151.203.201.149" date="29/Aug/2005" time="23:44:40" tzone="-0400">
<
method>GET</
method>
<
protocol>HTTP/1.1</
protocol>
<
status>200</
status>
<
bytes>73616</
bytes>
<
requri>/blogs/blogspinner/myblog-gantt-03.jpg</
requri>
<
referer>http://blogspinner.blogspot.com/</
referer>
<
useragent>Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.10) Gecko/20050716 Firefox/1.0.6</
useragent>
</
serverlogentry>
<serverlogentry id="2" clientip="68.96.55.133" date="30/Aug/2005" time="01:05:56" tzone="-0400">
<method>GET</method>
<protocol>HTTP/1.1</protocol>
<status>200</status>
<bytes>3282</bytes>
<requri>/blog/closeup-verysm.jpg</requri>
<referer>-</referer>
<useragent>Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)</useragent>
</serverlogentry>
</
logentries>
</
serverlog_partial>
The root XML element is defined by the <serverlog_partial> tag, which has the single attribute domain. This isn't strictly necessary, but I have multiple web domains that I'll be analyzing in the future. (I like to think ahead for future use of a software component.) Currently, the only child element of serverlog_partial is <logentries>, which has no attributes. The <logentries> element can have one or more <serverlogentry> elements. Each such element has 5 attributes:
id - This is a unique id that will be used in the server log database to identify each record. (My SQL-Tips blog is not live yet. Watch the the "My Tech Blogs" links list in the right column.).
clientip - This is the ip address of the visitor. For some web servers, this is actually the hostname, depending on how the server is configured. But that requires a
DNS lookup for each record, which is a waste of resources.
date - This is the date of a visit
time - This is the time of a vist
tzone - The time zone of your web server machine, relative to
GMT, Greenwich Mean Time. For example, I live in zone -0500, but my webserver is in -0400, or East of me by one zone.
The <serverlogentry< element has several children elements, none of which have any attributes:
<method> - This is the method by which the page was requested. It is usually GET or POST, but there are other values I won't discuss here.
<protocol> - This is the version of HTTP that is used by my web server. The only real reason I am saving this value is for posterity. [I'm a data junkie.]
<status> - This is the web server status code of the page request. A "200" is successful. A 404 is unsuccessful. There are other codes which I'll discuss in the Perl-Tips blog at a later time.
<bytes> - This is the exact number of bytes that resulted from a page request, whether it was successful or not.
<requri> - This is the
URI of the requested page. Note that an URI, or Uniform Resource Identifier, may be different from an
URL, or Uniform Resource Location. In particular, at least with my web server, the "http:/" portion is missing, and the values of requri are relative to the web server root directory.
<referer> - This is the web page from which the visitor clicked a link to request the current requri value. This is value is extremely useful in data mining techniques. It tells you where the visitor came from (i.e., they found your page). It can also tell you whether different advertising campaigns are successful or not.
<useragent> - This is the web browser or other software that the current visitor used to request this requri. In some cases, the operating system of the visitor's computer is also recorded. The useragent value is also extremely valuable for data mining. For example, it tells you which browser is most popular amongst your visitors. It also tells you which search engines are indexing your site.
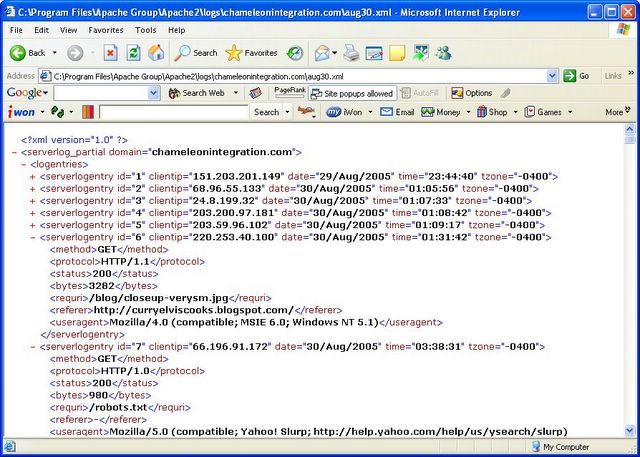
One thing to note is that this XML file is nearly twice as large as the original web server log file. So it's only a temporary data state in my web server log analysis system. The XML format that data is in, as shown above, is both to minimize the file size, as well as for human convenience. Particularly, if you view a syntactically correct XML file in an MS Internet Explorer browser, it gives you a display that allows you to expand and contract each node, or level, of markup. The two snapshots below illustrate. The first snapshot shows an XML file displayed in Internet Explorer with all the nodes expanded. In the second snapshot, the first few nodes have been collapsed.

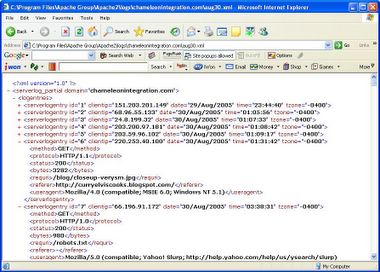

Notice that in the collapsed nodes, you can see at a glance which visitor each <serverlogentry> element represents, and what the date, time and zone was. For this reason, and to reduce file size, I used attributes in <serverlogentry> instead of making each value an XML element. [I support OpenSource software, but sometimes there is functionality in commercial software that isn't found elsewhere.]
Again, don't forget that I'll soon post the Perl code that generates WSML files over at my
Perl-Tips blog.
(c) Copyright 2005-present, Raj Kumar Dash, http://xml-tips.blogspot.com